생존형 개발 개미 로그2 - Node.js 크롤링 찍먹시작

서론
안녕하시렵니까 Shiny Ocean 입니다 : )
이번주에 해볼짓은 Node.js 랑 좀 친해져 보려구합니다~
근데 주제를 선정하다가..
맨날 출근하면 하는짓이 데이터 상하차 [http req, Json 하차, 쿼리조회, Json상차 , req 처리] 인데 퇴근하고도 상하차 하고싶지는 않네요~
저 웹 상하차짓을 Node.js로 구현하려해도(나중엔 하겠지만) 셋팅하는게 더 오래걸려용....
그래서 그나마 재밌는게 뭐가 있을까 하다가;;
작년 우리팀(이글스) 경기 결과 를 쭉 크롤링 해보려구용, 패배경기 최다 출전선수도 뽑아보고, 평균적으로 몇점수차로 지거나 이겼는지도 보고~
근데 DB 안쓸겁니다. CSV 나 TSV 파일로 결과 저장하는 크롤링 모듈짜려구용
저런걸 DB 쿼리 없이 하려면 데이터 객체 구성도 나름 이쁘게 해놔야할거 같아서 막 쉬울거 같지는 않고 구현하면서 Node랑 정확히는 자바스크립트 언어랑 좀 친해질거 같습니다.
환경 구성
IDE : VsCode
Language : JS
Execution env : node.js
Crawling npm lib : Puppeteer
설명쓰)
일단 IDE를 VsCode쓰는 이유는 이미 깔려있기때문입니다^^
언어는 당연히JS고 실행환경도 당연히 nodeJs 입니당
근데 크롤링용 라이브러리를 왜 퍼펫티어를 쓰는가 를 좀 이야기를 해볼께요
1. 동적 크롤링을 진행해야함
왜? 정적크롤링은 안되는가
크롤링 대상이 될 한화이글스 공식 홈페이지( https://www.hanwhaeagles.co.kr/index.do ) 경기일정 URI 구조를 좀 뜯어보면 날짜를 파라미터로 입력받아서 과거경기 결과 페이지에 접근이 가능하거덩요, 근데 야구가 맨날 하지 않아요~
예를들어 아래처럼 경기를 안한날을 억지로 파라미터로 던저서 접근하면 경기 결과데이터가 당연히 화면에 렌더링 되있지 않거덩요, 제가 저거 DOM 구조를 하나하나 분석해서 Data Exists 체크, display none 체크 같은거를 하나하나 일일이 하면 좋겠지만, 귀찮아요~

대신에 저 경기결과 페이지 이전페이지에 캘린더 UI를 살펴보면 빨간색 동그라미처럼 경기가 없는날은 데이터들이 비워져있어요
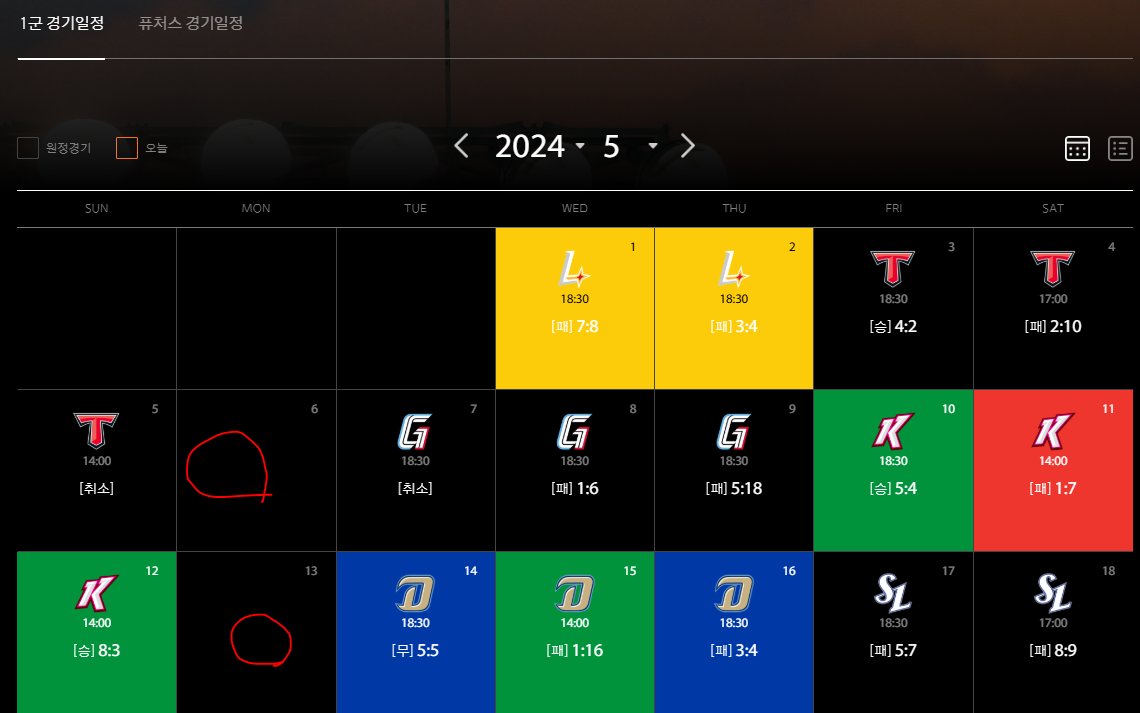
결론적으로 저 상위 월별 경기 결과 페이지에서 부터 동적으로 접근하면서 크롤링을 진행하면 좀더 편해보이더라구요~
2. 동적 크롤링 라이브러리중 왜 퍼펫티어인가
저는 원래 셀러니움으로 크롤링해본경험이 있거덩요, 근데 셀러니움 셋팅하는거 진짜 귀찮아요... 브라우저 드라이버도 깔아야하고... 그리고 정확히 노드 환경에서 셀레니움이 막강한 라이브러리인가에 대한 의문도 있었어요
그래서 요즘 세상에서 제일 똑똑한 개발선생님한테 물어봤죠 > 챗지피티
첨에 노드용 크롤링 라이브러리 중 동적크롤링을 지원하는거 추천해달라하니 퍼펫티어랑 플레이라이트 두개 추천해주더라구요
그래서 셀레니움이랑 비교해달라하니 아래 표를 던져줬습니다.

일단 종합적으로 제가 할짓? 은 요건이 무겁지 않습니다. 따라서 성능은 거기서 거기일꺼에요
근데 저는 환경 셋팅 하는걸 극단적으로 귀찮아해요... 잘 못해요 사실...
아니 수많은 가이드중 제대로된 셋팅법을 찾아서 읽고 그대로 따라하면 꼭 한두개씩 안되더라구요(거의 버전이슈)
그럼 또 안되는 부분을 찾아서 읽고 이해해서 되게해야하는데 그 과정을 제일 싫어합니다...
근데 저 표에 써있는 "설치 및 설정 부분"에서 퍼펫티어는 "상대적으로 간단" 이거하나때문에 픽했습니다.
환경 setting 스타트
1. 노드 설치
설치법은 구글링해서 다른 좋은 가이드 보세용~ 대신 설치 버전은 꼭! 18 버전 이상으로!
설치사이트 링크는 걸어둘께요!
Node.js — 어디서든 JavaScript를 실행하세요
Node.js® is a JavaScript runtime built on Chrome's V8 JavaScript engine.
nodejs.org
2. 노드 프로젝트 초기화
2-1 대상 디렉터리로 가서 "npm init" 명령하고 이름, 디스크립션, 버전같은거 설정하고싶은데로 하이소!
(저는 프로젝트 이름 빼고 다 스킵했어요)
2-2 node 실행환경 테스트
index.js 하나 파서 console.log 하나찍고 터미널에서 "node index.js" 실행해서 대강 결과 봤습니다.

2-3 실행 run & debug 탭에서 launch.json 파일 생성 누르고 대강실행하면 아래처럼 생성되는데
vscode 쓰는 사람만 디버깅 할수있을꺼에요 이제
3. 퍼펫티어 스타트
3-1 여러 가이드가 있지만 공식 사이트 를 참고하면
https://pptr.dev/guides/installation
Installation | Puppeteer
To use Puppeteer in your project, run:
pptr.dev
간단하게
"npm i puppeteer " ," npm i puppeteer-core " 이거 두개 깔고
"import puppeteer from 'puppeteer-core'; " 이거로 쓰면 된데용
바로 진행해보죠잉

3-2 getting start 찍먹
https://pptr.dev/guides/getting-started
Getting started | Puppeteer
Puppeteer will be familiar to people using other browser testing frameworks. You
pptr.dev
이슈 포인트 1
// syntaxerror: cannot use import statement outside a module
시스템 요구 사항
- Node 18+. Puppeteer는 Node의 최신 유지 관리 LTS 버전을 따릅니다.
-> 아주 극혐이죠 제 구닥다리 node 버전은 14에서 멈춰있었기에 문법오류가 뜨더라구요 재설치하고 다시 돌렸습니다.
이후)
대강 제 페이지 스샷찍는 법을 공식페이지에서 따와서
https://pptr.dev/guides/screenshots
Screenshots | Puppeteer
For capturing screenshots use Page.screenshot().
pptr.dev
대강 소스를 복붙하고
실행하니 퍼펫티어도 잘 깔린듯 싶습니다.

마무리
오늘 원래 그래도 환경파일 설정하고 타켓페이지 URL path 분석하는거 까지는 좀 작성하려했는데
뭐좀 깔고 셋팅했다고 시간이 은근히 많이 가버렸네요...
다음에 올께요!
다음 목표는 "크롤링" 행위를 하기 위해 대상 페이지 접근 시나리오를 짜볼꺼구요
크롤링 결과물을 초기화할 객체 구조를 좀 짜보고
시간이 남으면 실제 크롤링해서 콘솔로그 찍는거 까지 한번 해볼께요