
티스토리 뷰

안녕하세요 :)
이번 포스팅에서 다루어볼 주제는 Virtual memory(가상 메모리) 입니다.
지난시간 우리는 프로세스를 각각의 덩어리로 나누지만 전부를 메모리에 올려 사용하는 simple 페이징기법과 세그멘테이션 기법에 대하여 알아봤습니다. 이번 포스팅에서는 프로세스의 조각을 전부 올리는것이 아니라 최소한의 조각만 올렸다가 필요해지면 다른조각을 올려서 사용해보겠습니다.
그런데 본질적으로 이상하죠? 메모리에 프로세스 일부분만올라갔는데 메모리 폴트가 안나고 실행이 가능하다? 가능합니다! 실제로 메모리 참조는 런타임(일부분이 실행될때)에 물리주소로 바인딩되기 때문입니다. 그러니 실행되는 그 순간에만 실행되는 일부분이 물리메모리에 올라와 있다면 된다는것이죠!
그로인해 프로세스는 조각조각 나뉘어서 메인메모리에 비연속적으로 배치될수 있고, 실행도 가능합니다.
지금부터 이 내용을 활용해서 조금더 머리는 아프지만 조금더 똑똑하게 메모리를 운영해 볼것이기때문입니다.
이전포스팅의 예제는 조각 조각 쪼개어 올렸지만 프로세스의 전부를 올렸었습니다. 하지만 이번 포스팅에서는 실행에 필요한 최소한만 올릴것이고 다른조각이 필요해지면 그때 바로 올려서 사용할것입니다.
가능할까요?
일단 ok라 치고, 최소한의 조각만 올리고 다른조각이 필요해졌습니다. 그럼 디스크에서 검색을 해야하겠죠? 하지만 디스크의 속도는 어떻습니까? 메인메모리보다 현저히 떨어집니다. 그럼 CPU의 실행속도가 메모리에 올라오는 속도보다 매우 빠르니 바로 폴트날 것입니다.
하지만 이번 포스팅에서 다루게 되는 Virtual memory의 개념을 사용하게 된다면 이는 해결될 것입니다. 어떻게 해결될것인지 찬찬히 시작해 보겠습니다.
Virtual memory란?
main memory + second memory(디스크의 일부분을 메모리로 사용한것) 입니다.
Reak memory의 경우 물리적으로 존재하는 메모리 자체입니다.
만약 4기가 램이라면 4기가의 제한이 존재하겠죠, 하지만 가상메모리(Virtual memory)의 경우 Reak memory의 크기 제한을 풀어줄수 있습니다.
그럼 페이징 기법에도 변화가 생길것입니다. 기존에 다루었던 simple 페이징의 경우 프로세스가 수행되기 위해서 모든 페이지가 메인메모리에 올라와 있어야 했습니다. 하지만 이번에 다루어볼 virtual memory 페이징은 모든 페이지를 메인메모리에 올리지 않고 필요할때마다 올리면 됩니다.
하지만 필요할때마다 올릴경우 이미 메인메모리에 올라와있는 페이지를 또다시 올려서 사용할수도 있겠죠? 이와 같은 문제도 천천히 다루어 보겠습니다.
Principle of Locality
위와 같은 가상 메모리가 어떤 원리로 가능한지 조금 다루어 보겠습니다.
- 메모리에서 참조하는 부분은 한군데에 몰려있기 때문입니다. 디스크 내에 메모리가 참조하는 부분은 쪼금씩 분산되어 있는것이 아닌 덩어리로 몰려있습니다.
디스크 전부를 다시 검색하여 참조 부분을 다시 찾아내고 올린다면 속도가 느린 I/o 디바이스의 특성상 가상메모리 시스템의 실현가능성이 없겠지만! 메모리 참조부분이 한군데 몰려있다면 그부분만 검색하면 되기 때문에 속도가 향상됩니다.
virtual memory paging
simple paging기법과는 달리 시스템에서 사용하는 페이지의 주소체계는 다음과 같습니다.
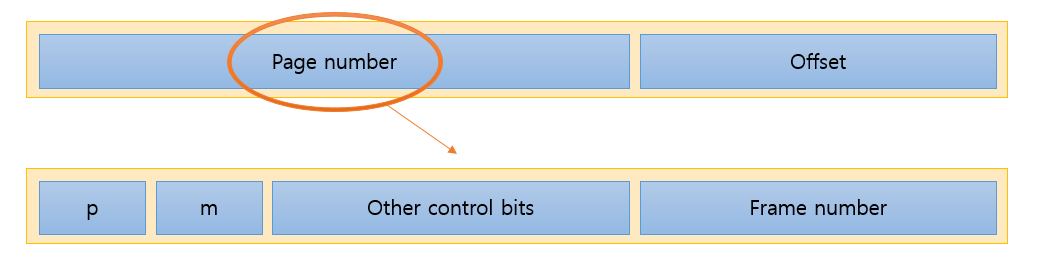
제일 먼저 눈에 들어오는것은 page number의 크기 입니다 simple paging에 비해 엄청 커진것을 확인할수 있습니다. 그리고 구성요소도 엄청들어난 것을 확인할수 있습니다. 하나씩 다루어 보겠습니다.
Presnet bit(p)
해당 page가 메인 메모리에 올라와 있는지 아닌지를 알려주는 비트입니다. 앞서 언급한 것과 같이 필요한 페이지가 생길때마다 다이나믹하게 올려서 사용하는 virtual memory 페이징 기법은 이미 메인메모리에 올라와있는 페이지를 하나 더 올려서 사용할수 있기 때문에 p비트를 통해 이미 올라와있는지 여부를 판단하고 활용할수 있습니다.
modify bit(m)
해당 페이지가 메인메모리에 올라온 이후 수정이 되었는지 알려줌, 수정이 안된 페이지라면 교체할때 디스크에 다시 쓰지 않아도 됨,(수정된 페이지라며 수정사항을 반영해 놓아야 한다)
other control bit
보호와 소통을 위한 비트(protection, sharing)
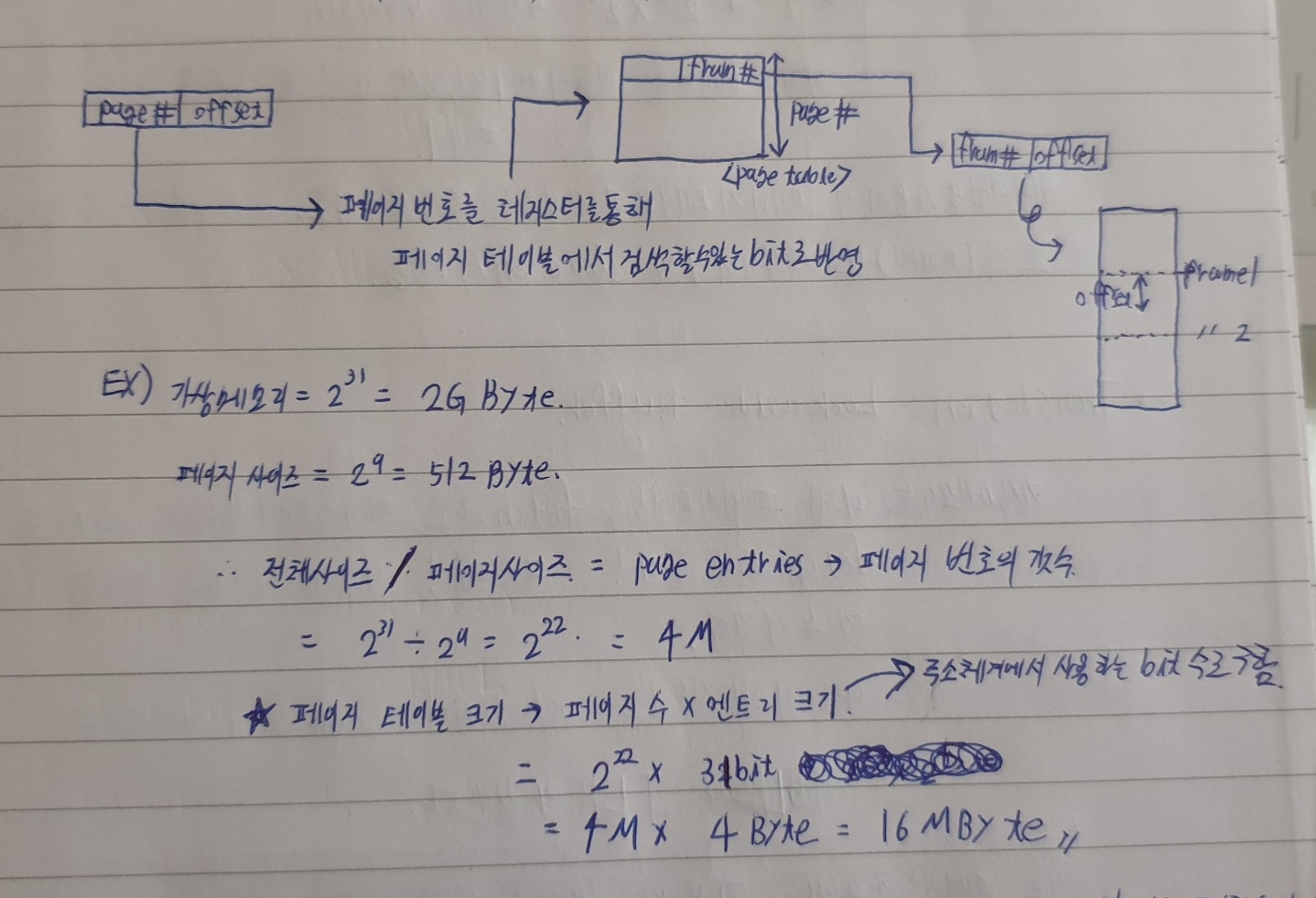
위와 같은 예제를 살펴 보면 페이지 테이블의 크기가 사용하는 주소체계에 따라서 엄청 커질수 있습니다. 메인메모리의 용량을 초과해서 다 올리지 못하겠죠...? 배보다 배꼽이 더큰 상황이 일어납니다.
그러면! 페이지 테이블도 조각내어서 일부만 사용하겠습니다.
어떻게 페이지 테이블을 조각내어 사용할까요? Use two level scheme to organize large page table
두단계의 테이블을 사용해서 큰테이블을 유기적으로 배분해주는 것입니다. 아래와 같습니다.

위의 기법을 사용하여 페이지 테이블의 사이즈를 조각내어 주고 프로세스가 실행될때 해당 조각(페이지) 또한 다이나믹하게 load해서 사용합니다.
Translation Lookaside Buffer(TLB)
가상 메모리는 이제 페이지테이블을 fetch하고 페이지테이블 내의 data도 fetch해야 합니다. 그런데 이렇게 두단계를 거치면 속도가 느려집니다. 이를 위해 사용하는 솔루션이 high-speed cache입니다.
이를 TLB라 합니다.
이는 페이지를 찾을때 TLB라는 버퍼를 먼저 검색하는 것인데, 이 버퍼에는 기존에 사용한 이력이 있는 페이지의 실제 주소가 저장되어있습니다. 두단계 페이징 기법을 사용한 결과값이 다이렉트로 저장되어 있는것입니다.
메인메모리에서 프로세스의 페이지를 로드할시 TLB에서 먼저 검색하고 만약 TLB에 찾고자하는 정보가 있다면 TLB hit라 하고 못찾는다면 TLB miss라 합니다. miss시 페이지 테이블을 검색하던 기존 두단계 로직을 수행후 page를 메인메모리에 로드 합니다. 이후 다시 TLB를 검색합니다. 만약 miss인 상태인데 메인메모리에 올라와있다면 해당사항을 TLB에 업데이트 하고 프로세스를 수행합니다.
-Talk about page's size
페이지의 사이즈에 대한 이야기를 조금 해보겠습니다.
page의 크기가 작다 -> 메인메모리에 프로세스당 할당가능한 frame의 갯수가 증가한다 ->fault가 낮아집니다.
page의 크기가 크다 -> locality 이상이 하나의 페이지에 포함된다면 fault입니다. 하지만 그이상으로 사이즈가 비대해져서 한 프로세스를 다 포함할정도가 된다면 fault의 비율이 낮아지게 됩니다. 하지만 그렇다면 페이징 기법을 사용하는 의미가 없어지겠죠.
Invert page Table
정보를 반대의 순서로 저장 -> frame에 대한 정보를 이용하여 역으로 테이블을 찾는다. 몇몇개만!
아무리 2레벨 로 나눈다고 하더라도, 또는 그 이상의 레벨로 나눈다 한다고해도 fetch를 한번이상 해야 한다는점과 테이블의 크기가 크다면 효율이 떨어진다는 점에서 다른 방식을 고안해볼 필요가 있습니다. 그래서 Invert page Table입니다.
특징)
- 글로벌한 페이지 테이블이 하나 존재한다.
- 물리 메모리 기준에서 정보를 저장한다. - 각 프레임 마다 정보를 저장
- 전체 시스템에서 인버트 페이지 테이블은 딱1개 이다.
- 가상 주소의 페이지 번호를 hash값으로 매핑한다.(테이블 엔트리 번호 + 물리 프레임 번호)
구성요소)
- 페이지 번호 - 프로세스 ID - control bit - chain pointer
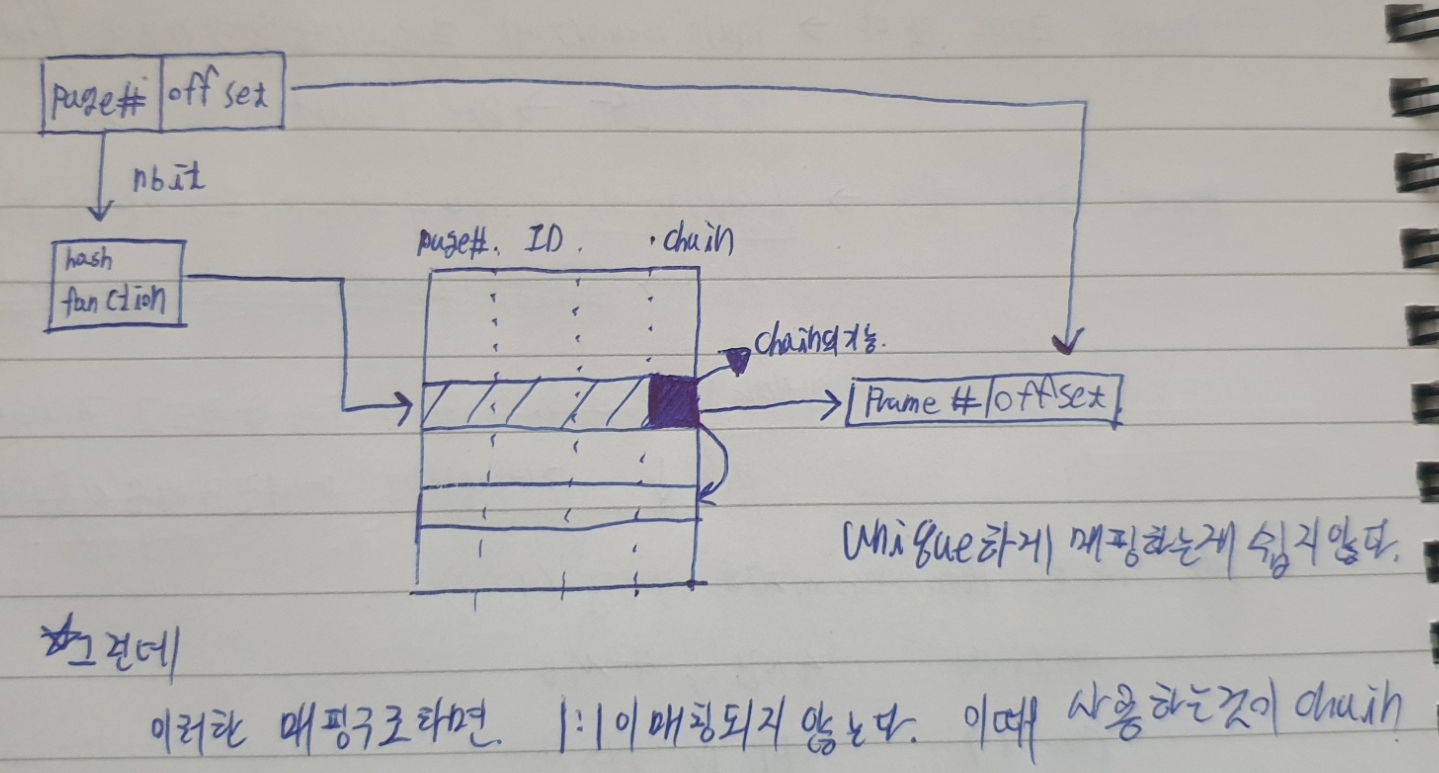
chain pointer - 해시맵에 시도시, 타겟 인덱스에 이미 값이 매핑에 되어있다면 다른곳으로 포인팅해준다 (중복을 허용하지 않기 위해)
segment table
segment의 크기는 가변적이다. data allocation을 중점으로 다루어야 한다.
구조는 아래와 같습니다.
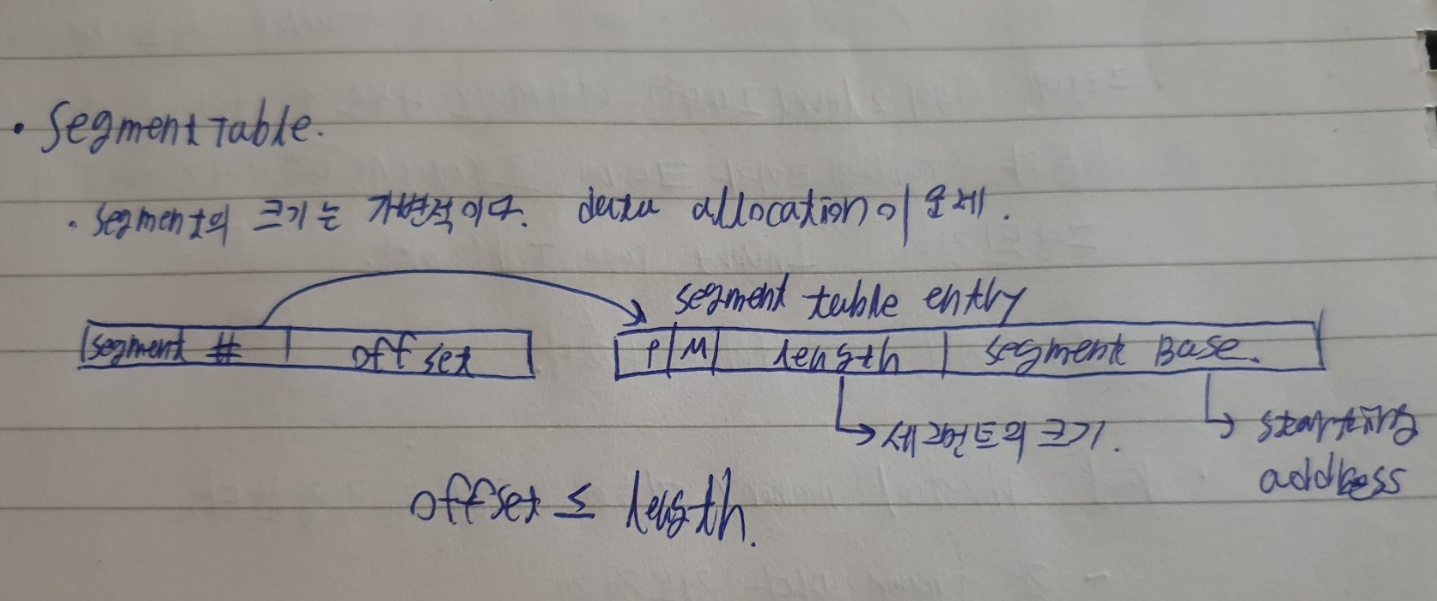
로직)
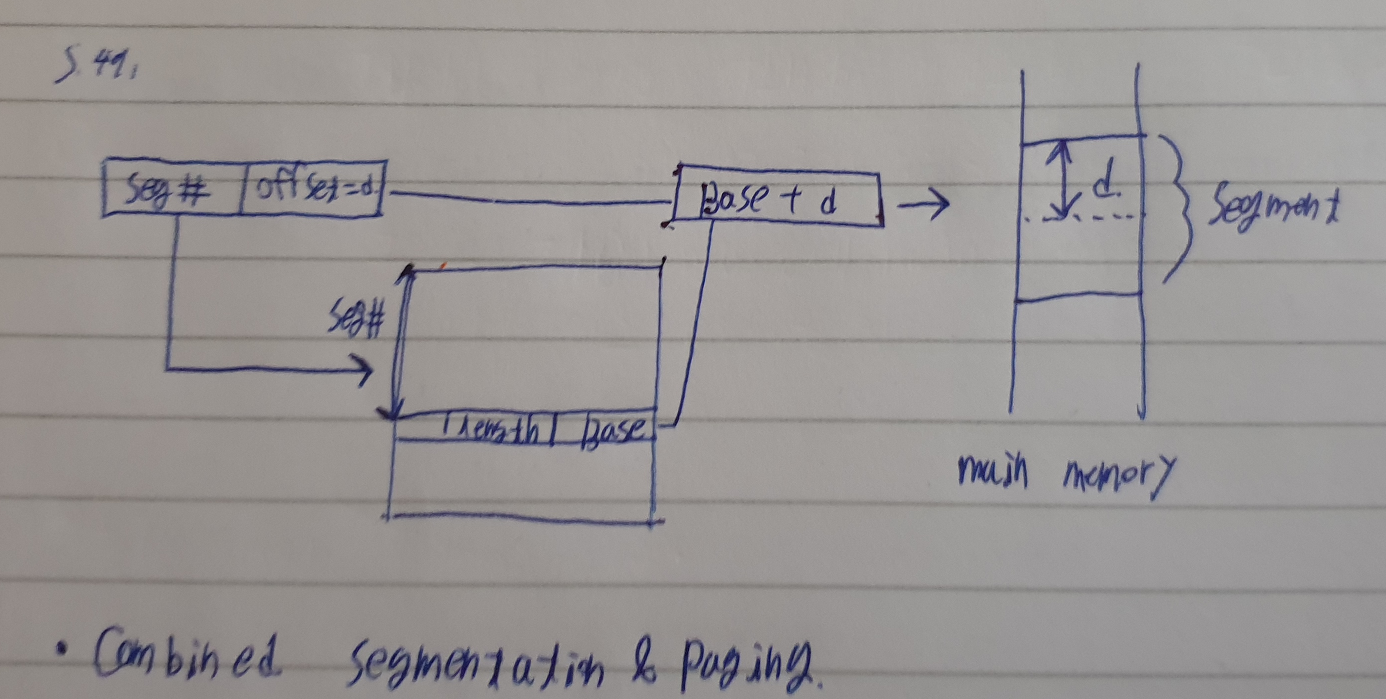
우리는 지금까지 가상메모리환경에서 페이징 기법과 세그멘테이션 기법에 대하여 다루어 보았습니다.
각각의 장점을 한번 정리해보겠습니다.
먼저 페이징 기법은 같은 크기의 페이지로 메인메모리와 페이지가 잘라지기 때문에 위치할당에 용이합니다. 어디든가능하니까 말이죠! 또 이러한 이점으로 인해 외부단편화가 일어나지 않습니다.
세그멘테이션 기법의 장점은 개발자에게 visable 합니다. 그리고 개발에 용이합니다. data의 구조가 자라나는것을 핸들링하기가 쉽기 때문이죠! 컴파일 이후에도 독립적으로 공간할당도 허용하고 가장 좋은점은 share와 protection에 유용하다는 점입니다.
그렇다면 이와같은 두기법의 장점을 살려서 섞어볼순 없을까요? 가능합니다.
아래의 구조와 같습니다. 이를 Combined segmentation & paging이라 합니다!
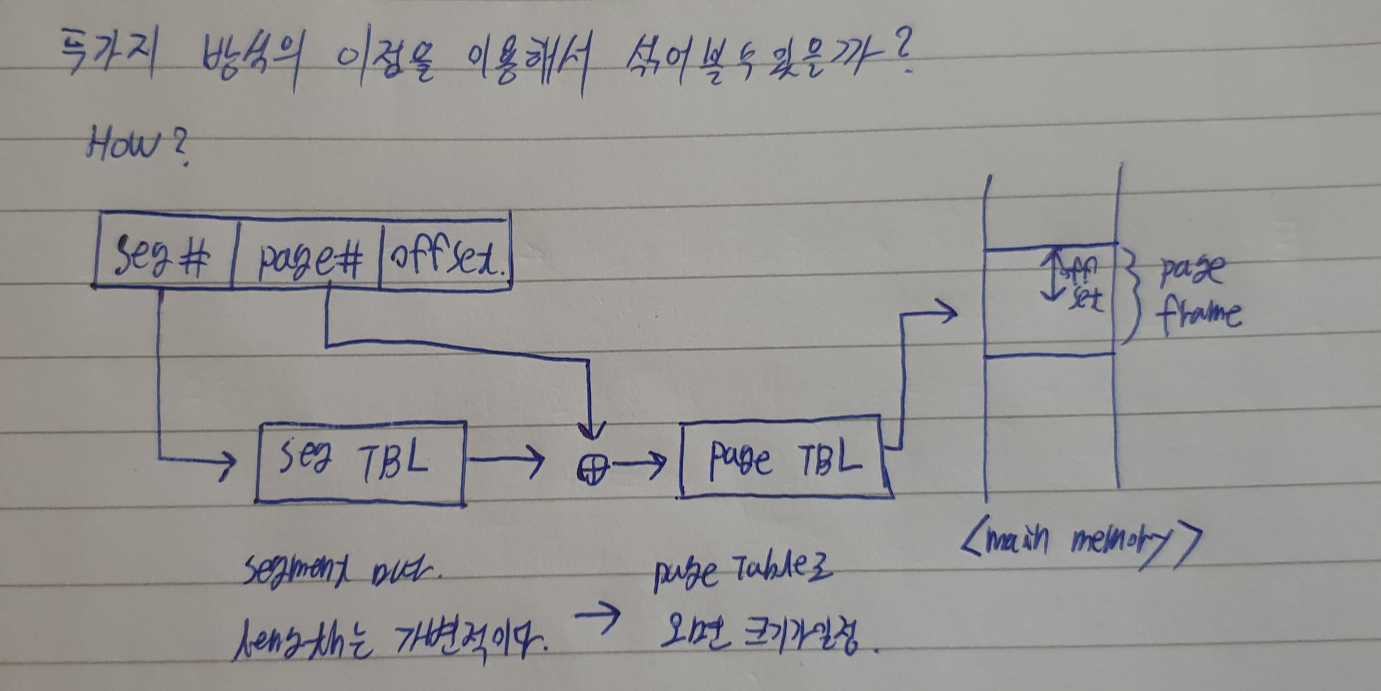
이번에는 page를 어떻게 올리는지에 대하여 다루어 보겠습니다.
첫번째로 고려해볼 사항은 어느 시점에 page를 올리는가 입니다.
Fetch policy
-Demand paging, 가장 마지막까지 미루다가 page를 메인메모리에 올리는 방식으로 수행중에 해당 페이지가 필요해지면 그때 메인메모리에 올려서 수행합니다.
-Prepaging, 수행중 필요한 page를 예측해서 올려두는 방식입니다.
두번째로 고려 해볼 사항은 페이지를 메인메모리의 어디에 올리는가 입니다.
placement policy
세그멘테이션 기법을 다루어봤을 때 다루었을때 다루었던 best fit, first fit, next fit들이 이사항에 포함될것 같습니다.
반면 페이징기법과 세그멘테이션 기법을 혼용한 기법은 결과적으로 마지막에 페이지로 반환되기 때문에 메인메모리의 비어있는공간 아무곳에 넣어도 될것 같습니다.
마지막으로 고려해볼 사항은 이미 메인메모리가 가득찼다면 어떻게 할 것인가 입니다.
Replacement Policy
메인메모리 내에 페이지가 할당된 프레임중 적당한것을 선택해 디스크로 swap해주고 새로운 페이지를 할당해주면 해결될것같습니다. 이때 전체 페이지 중 실제로 main memory에 올라와 있는 부분을 Resident set이라 합니다.
Resident Set을 관리 할때 고려해야할점은 어떤것을 빼내어 swap할까일것입니다. 지금부터 한번 깊게 생각해보겠습니다.
가장 이상적인 방법은 무엇일까요?
이제 앞으로는 안쓰일 page를 빼내고 남은 그 자리에 새로운 page를 할당해 주는것일것입니다. 하지만 미래에 대한 예측은 예측일 뿐 사실상 불가능합니다. 그래서 가장가까운 과거를 보고 판단하는 알고리즘을 수행해볼것입니다.
+@ Frame Locking
프레임을 교체하는 과정에서 지금 당장은 안쓸수도 있지만 없어지면 안될 페이지도 존재할것입니다. 예를들어 웹브라우져를 통해 유튜브 영상을 4K로 3시간 이상 시청한다 가정하겠습니다. 당장은 고화질 영상을 버퍼링없이 재생하기 위해 메인메모리의 프레임을 많이 할당해 주어야 하지만, 윈도우창을 닫을때 사용하는 프레임마저 빼내면 안될것입니다. 함부로 빼냈다가 앞으로 컴퓨터를 이용시 창을 못닫는 불상사가 생길테니까요!
이처럼 운영체제의 커널 부분, structure를 컨트롤하는 부분, I/o buffer 등의 프레임을 빼내지 못하게 잠구는 것을 Frame Locking이라합니다.
이제 프레임 교체에 필요한 네가지 알고리즘에 대하여 다루어 보겠습니다.
Basic Algorithms
- optimal
가장 이상적인 솔루션으로서 미래에 대한 예측이 불가능함으로 실현가능성은 존재하지 않습니다. 하지만 이상적인 방안을 생각해 봄으로서 다른 솔루션들의 성능 평가에 대한 만점기준이 될수 있습니다.
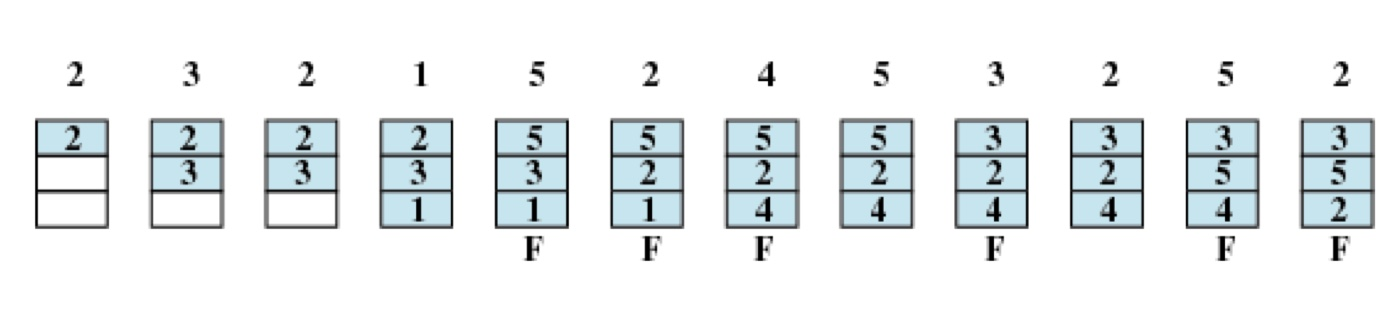
만약 p2 p3 p2 p1 p5 p2 p4 p5 p3 p2 p5 p2 순서로 페이지를 프레임에 할당한다하고, 프레임의 갯수는 3개라고 해보겠습니다.
그렇다면 세개씩 꽉채워진 프레임순서는 다음과 같습니다.
(p231), (p235), (p435), (425) or (235)
가까운 미래에 사용되지 않는 페이지와 새로운 페이지를 교체하는 방식입니다.
- Least recently used(LRU)
위에서 다루어본 optimal 솔루션의 경우 미래의 페이지 할당에 대한 정보를 알고 있다는 가정이기 때문에 베스트한 솔루션이 될수 있지만 우리는 실제로 페이지를 할당할때 미래에의 정보를 알수 없습니다. 그래서 고안된 방법이 과거의 기록을 살펴서 가장 최근에 사용하지 않은 페이지를 지우고 새로운 페이지를 할당하는 LRU방식입니다.
똑같이 p2 p3 p2 p1 p5 p2 p4 p5 p3 p2 p5 p2 순서로 페이지를 프레임에 할당한다하고, 프레임의 갯수는 3개라고 해보겠습니다.
(p231), (p251), (p254), (p354), (p352)
그런데 마지막에 세개의 과정을 살펴보면 2번 페이지를 빼서 다른 페이지를 할당하자마자 다시 2번 페이지가 필요해져서 다시 할당한 경우가 발생했습니다.(이 과정 같은경우 효율이 별로 좋지 않을것입니다)
그리고 LRU 방식의 대표적인단점은 overhead을 요구 한다는 것입니다. 이는 가장 최근에 사용한 페이지가 무엇인지 판별하기 위해 페이지 사용시 도장을 찍어, 도장을 찍은 시간과 현재시간의 상대적인 차를 이용하는 방식을 사용하는데, 이때 도장 데이터에 대한 별도의 overhead를 요구하게 됩니다.
-FIFO (first in first out)
가장 무식하고 단순한 로직입니다. fifo 큐의 방식처럼 제일 오래된 페이지가 나가는 aging기법을 사용하는것인데 구현이 심플하다는 장점이 있겠지만 그만큼 효율면에서는 꽝입니다. 메인메모리에 들어있는 페이지가 아닌 새로운 종류의 페이지가 프레임을 요구할때마다 fault일 테니까요!
이 단순무식한 로직을 조금 개선한 방법이 클럭을 사용하는로직입니다.
- Clock Policy
use bit 이라는 비트를 추가하여 해당페이지가 참조된적 있다면 1 없다면 0으로 초기화해서 사용하는 방식입니다.
fifo 방식과 비교한 결과는 다음과 같습니다.

Variable Allocation, Local Scope
-새 프로세스르르 로드할때, 어플리케이션의 종류나 프로그램의 요청등의 기준을 기반으로 고정된 갯수의 프레임을 할당해줌
-page fault가 발생하면 자신의 frame 중 하나를 선택하여 교체, 운영체제가 정기적으로 프로세스의 메모리 사용실적을 판단하여 할당된 프레임의 갯수를 조절한다.
어떻게? 두개의 알고리즘이 존재합니다.
page fault frequency(PFF)
로직은 간단합니다. usebit을 이용하여 페이지가 참조되었는지 여부를 기록하고 일정 시간의 구간동안 fault가 빈번하지 않다면 usebit이 0인(참조되지 않은)페이지는 빼고 남아있는 페이지의 usebit을 1에서 0으로 바꿉니다. 그리고 남아있는 페이지의 갯수에 딱맞게 프레임의 갯수를 줄여줍니다.
만약 fault의 비율이 빈번 하다면 프레임을 늘려주고 시간의 구간도 늘려줍니다. 이때 늘어난 프레임에서의 use bit은 늘어나기 이전과 동일합니다.
하지만 참조가 이동한다면 계속 fault가 일어날것이고 필요 이상의 frame이 생성될 것 입니다.
(새로운 페이지만 계속 참조될 경우를 이야기합니다)
위의 문제를 개선한 알고리즘이 다음과 같습니다.
Variable - interval sampled working set (VSWS)
fault와 fault사이의 간격을 보지 않고 고정된 간격으로 지켜보는것입니다. 고정된 interval을 보고 결정하기 때문에 새로운 프레임을 하염없이 생성해 내지는 않습니다.
이는 시작시 Q라는 횟수를 최대 허용치로 fault를 관찰합니다. 만약 샘플링 시간의 최소치인 M시간 이후에 Q의 횟수가 허용치를 넘어설경우 샘플링을 진행합니다. L이라는 최대 허용치가 된다면 Q의 발생 횟수와는 상관없이 무조건 샘플링을 진행합니다.
'Major > Operating System' 카테고리의 다른 글
| Operating System - Memory Management (0) | 2021.05.29 |
|---|---|
| Operating System - Deadlock & Starvation (1) | 2021.05.29 |
| Operating System - Mutual Exclusion (1) | 2021.04.14 |
| Operating System - Treads (1) | 2021.04.14 |
| Operating System - process description & control (0) | 2021.04.14 |